
图片逼真程度是否依赖于像素差?
答案看似肯定,实则不然。
图中两组生成样本,对应的目标为“2”,上面的两个样本虽然只相差一个像素点,但是这个像素点对于全局的影响很大,下面的两张图差了六个像素点(粉色部分的像素点为误差),但对于整体判断影响不大。
如果直接使用损失函数,结果是下图差距比上图大。而判别器则不拘束于具体像素差距,可以更好地判断图片。

这就是生成对抗网络GAN的意义。GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator),生成器的目标是欺骗判别器,判别器的目标是检测伪造数据。因此,在训练过程的每次迭代中,都会更新生成网络的权重以增加分类误差(误差梯度在生成器参数上的上升),而判别网络的权重将进行更新以减小此误差(判别器参数的误差梯度下降)。二者不断对抗,机器通过深度学习更能够把握全局信息。
可以想象,在生成器和判别器的不断博弈下,GAN最终的生成图片可以达到以假乱真的效果。
嗅觉灵敏的开发者领悟到GAN的划时代意义并积极布局。2022年上半年,JUNLALA就开发出了首款基于图像的生成对抗网络算法。至2022年底,JUNLALA已推出升级版GAN算法。新算法可以生成更加逼真与具体的图像, 达到人工智能图像生成的最高标准。
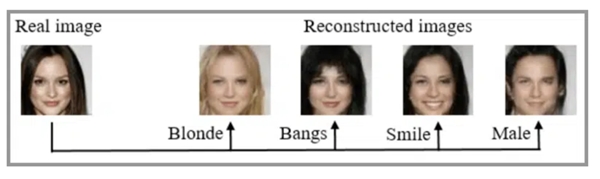
该算法在实践层面的功能比想像中更加强大。它可以生成现实照片、动画角色,也可以进行图像转换,例如将卫星图像转化成谷歌地图、将黑白图片转化成彩色图片、将夏景转化成冬景等,还可以完成文字到图像的转换、在语意-图像-照片之间自由切换,在各个行业广泛应用。

图片生成功能
此外,GAN还提供提高照片分辨率、照片任意编辑、预测不同年龄的长相、照片修复、自动生成模型、通过人脸照片自动生成对应的表情等功能。
照片编辑功能

提高分辨率功能
更厉害的辅助功能是,GAN生成的图像数据集可以助力人工智能训练。人工智能的训练需要大量数据集,全靠人工收集和标注成本高昂。GAN可以自动生成数据集,提供低成本的训练数据。在自然语言处理中应用,GAN的研究也是一种增长趋势,如文本建模,对话生成,问答和机器翻译。据统计,JUNLALA基于GAN算法训练的AI模型均采用深度学习方法,其中图片生成模型参数在5-10亿,对话模型参数在10亿以上。
可以说,GAN这种全新技术在生成方向上带给人工智能领域全新的突破,其作为一种无监督深度学习模型,将图片从单独图片的概念中跳脱。创作者不再拘泥于“就图论图”,而是给事后纠偏及再创作留下大量空间。
尽管JUNLALA推出的GAN算法在图片生成与对话模型均已达到业界先进水平,但JUNLALA追寻的目标绝不止于此。GAN的出生基因就注定了它会一直更新学习,这也正如JUNLALA的创始理念一样——不断突破自我,不断创新,鼓励提出新想法。墨守陈规的公司始终会被淘汰,不妨做改变世界的那一个。
在落地应用层面,GAN还有更多可拓展的空间。近期AIGC爆火的背后,正是有GAN作为推手。在GAN的“助攻”下,JUNLALA等平台为用户提供了低门槛创作渠道。在图片创作领域,GAN不仅可以出色地完成任务,且兼具艺术欣赏价值。2018年,由GAN创建的Edmond Belamy的肖像在佳士得拍卖会上以432,500美元的价格成交。
值得一提的是,JUNLALA的创始人表示,GAN算法有望在相关领域获得较大应用。也就是说,尽管GAN算法的出现已经在很大程度上解放了创作者的双手,并在不同领域发光发热,但在应用层面,GAN的应用价值还有更大潜力可供挖掘。我们期待JUNLALA为用户提供更加全面、精准的服务体验,同时随着技术的不断发展有更广泛的应用场景与更出色的表现。
新财网对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。读者应详细了解所有相关投资风险,并请自行承担全部责任。本文内容版权归新财网投稿作者所有!文中涉及图片等内容如有侵权,请联系编辑删除。











 账号注册
账号注册